搜索引擎工作过程非常复杂,今天和大家分享一下我所了解的百度蜘蛛是怎么实现网页收录的。
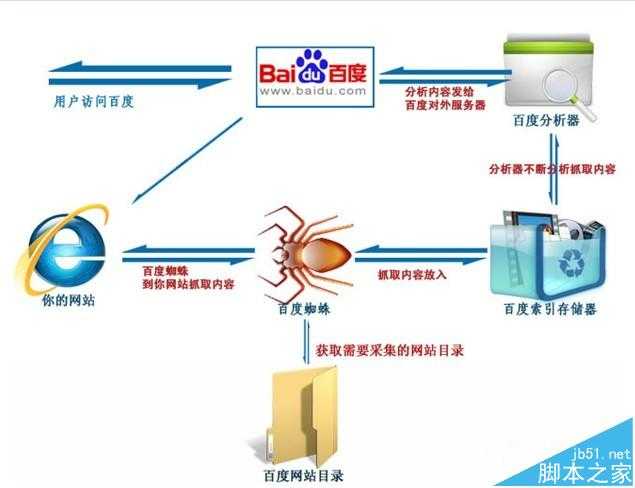
搜索引擎工作大致可以分为四个过程。
1、蜘蛛爬行抓取。
2、信息过滤。
3、建立网页关键词索引。
4、用户搜索输出结果。
蜘蛛爬行抓取
当百度蜘蛛来到一个页面时,它会跟踪页面上的链接,从这个页面爬行到下一个页面,就好像一个递归过程,这样常年累月,不止疲倦的工作。比如蜘蛛来到了我的博客首页http://blog.sina.com.cn/netSEOer,它会先读取根目录下的robots.txt文件,如果没有禁止搜索引擎抓取,那么蜘蛛就开始针对网页上的链接,进行逐一跟踪爬行。比如我的置顶文章“SEO概述|什么是SEO SEO到底是干嘛的”,引擎就会多进程式的来到这篇文章所在的网页抓取信息,如此循坏,没有终结。
信息过滤
为了避免重复爬行和抓取网址,搜索引擎会有一个记录已爬行和未被爬行的地址库,如果你有一个新网站时,你可以去百度官网提交网站的网址,引擎就会记录它,并把它归类到未爬行的网址,然后蜘蛛就会根据这个表格,从数据库中提取URL,访问并抓取页面。
蜘蛛并不会收录所有的页面,它要经过严格检测。当蜘蛛在爬行和抓取一个网页的内容时,会进行一定程度的复制内容检测,如果网页所在的网站权重低,而且大部分文章都是抄袭来的话,蜘蛛就很可能不喜欢你的网站了,不在继续爬行,也就不收录你的网站。
建立网页关键词索引
当蜘蛛抓取了一个页面之后,首先会对页面文字内容进行分析。通过分词技术,将网页的内容简化到关键词,并把关键词和对应的网址制成表格建立索引。
索引又有正向索引和反向索引,正向索引是把网页内容对应的关键词,反向是关键词对应的网页信息。
输出结果
当用户搜索了某个关键词之后,就会通过前面建立的索引表进行关键词匹配,通过反向索引表找到关键词对应的页面,通过引擎对网页综合评分计算以后,根据网页的评分来决定网页的先后顺序排名。
相关推荐:
网站优化 百度蜘蛛到底喜欢什么?
怎么查询ip是否为百度蜘蛛ip? tracert指令的使用方法
百度,蜘蛛收录
更新日志
- 徐璨宾《井底的蚯蚓》[320K/MP3][78.77MB]
- 碧蓝航线国庆金秋版本重磅上线 新玩法3D宿舍系统闪亮登场
- 自在西游自在服即将在10月1日开启 入驻即享豪礼满满
- 炉石传说最强术士卡组是哪个 术士最强天梯卡组推荐一览
- 炉石传说最强萨尔卡组是哪个 萨尔最强天梯卡组推荐一览
- 炉石传说最强潜行者卡组是哪个 潜行者最强天梯卡组推荐一览
- 银霞.1983-《爱迷惑我·我住小楼中》台湾复刻版[WAV+CUE]
- [雨果唱片]粤曲名家-《再折长亭柳》[WAV+CUE]
- 刘德华1998-你是我的女人[香港第二版][WAV]
- 压迫感谁最强?外媒评选恐怖游戏最佳女反派
- 还没正式发售:《寂静岭2:重制版》Steam玩家峰值近9000人
- 别搞政确了!超95%国外玩家反对强制包容性
- 《暗喻幻想:ReFantazio》试玩:ATLUS的自我挑战?
- 《憧憬成为魔法少女》第二季 反转魔法少女题材再掀热潮
- 海信AI电视E7N正式发布,引领AI画质新标杆